There is plenty of talk about Data Virtualization , also known as the Logical Data Warehouse. You can read anywhere about the virtues and cost savings of using Data Virtualization ("DV") in many scenarios. I tend to believe that Data Virtualization is one of the most important new trends in data management in at least a decade, drawn in, finally, by the great Big Data reality and the ensuing demand for efficiency in funneling data to non-technical business analysts, data scientist, as well as the average business user. Instead of spending months to accumulate and correlate data from various sources, it is possible to provide the data in a matter of hours or days.
There is plenty of talk about Data Virtualization , also known as the Logical Data Warehouse. You can read anywhere about the virtues and cost savings of using Data Virtualization ("DV") in many scenarios. I tend to believe that Data Virtualization is one of the most important new trends in data management in at least a decade, drawn in, finally, by the great Big Data reality and the ensuing demand for efficiency in funneling data to non-technical business analysts, data scientist, as well as the average business user. Instead of spending months to accumulate and correlate data from various sources, it is possible to provide the data in a matter of hours or days.
I also believe that the companies that adopt Data Virtualization promptly will discover that they have naturally developed a competitive advantage over their rivals.
So, this is data virtualization: The ability to define virtual data models from multiple totally different sources with validation and logic, and provide these as query-able services. Instead of a cumbersome Data Warehouse, the data resides at the sources with logical federation happening when it is queried. Of course, each Data Virtualization product uses its own techniques and constraints to build and execute its models, and certainly some are more agile than others.
What Makes Some Data Virtualization Products Agile?
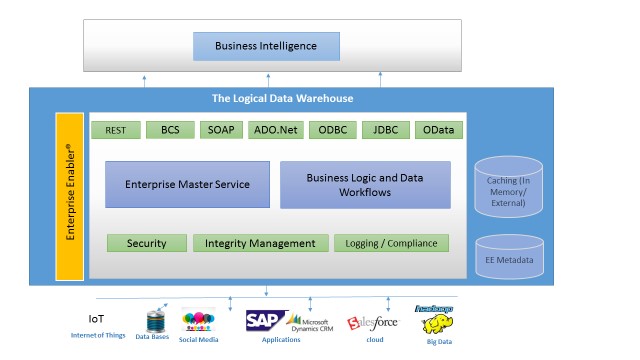
Most Logical Data Warehouse products are Plain Vanilla as opposed to Agile. Stone Bond Technologies’ Enterprise Enabler® (“EE”) has had data federation and virtualization at the core of its product for more than twelve years, first with Agile ETL. EE’s transformation engine handles multiple live simultaneous sources in parallel, applying federation rules, validation rules, and business rules and formulas as the data is processed directly from the sources and delivered to the desired destination in whatever form is required. Those executions are initiated by a trigger (“push”).
This is the same logic that EE uses to handle all of the logic for Data Virtualization, on-demand / query-able virtual model (“pull”).
Because of the roots of Agile ETL that drive Enterprise Enabler’s Data Virtualization, its DV inherently can incorporate all kinds of options for caching, data validation incorporating lookups from external sources, and even end-user aware write-back to the sources.
Write-Back to the sources is a powerful feature that promotes agility and expands the scope of what can be expected from a DV solution. This feature is the key to realizing Gartner’s “Business Moments.”
Some Agile DV Characteristics to Look for
Note that these points do not cover the features that are generally expected in every DV product.
· Single Platform. Enterprise Enabler is an all-in-one environment for configuring, testing, deploying, and monitoring all virtual models and executions. Design-time validation also contributes to never needing to leave the Environment.
· Metadata Driven. Enterprise Enabler is 100% metadata driven. There is never a need to leave and use any other tool.
· Reusability. All business rules, formulas and configured objects such as Virtual Models are reusable.
· Repurposing. Within a couple of minutes, a virtual model can be re-caste as an Agile ETL, which, when triggered, streams the data simultaneously from the sources, applies the same logic and validation rules, and posts it to the indicated destination in exactly the required format.
· Robust Transformation Engine. The transformation engine gets data from all sources in their native mode, so there is no staging step involved. The transformation orchestrates across the sources to apply the configured semantic alignment, validation and formulas.
· Embedded code editors/test environment/compiler. When the logic becomes very complicated, sometimes it is necessary to pass code snippets to the transformation engine. The code snippets become part of the metadata and are managed within the platform itself.
· No Restrictions on Data Sources. Literally.
· Data Workflow. In real-life situations, it is common to need some kind of data workflow, processes and notifications, for example, in making BI dashboards actionable without leaving the DV platform. If you think that’s not part of DV, maybe you’re right. But is definitely is needed in Agile DV.
· Auto-generation and hosting of Services. Soap 1.1, 1.2, REST, Odata, SharePoint, External List, ADO.Net. Accessible via ODBC, JDBC, MySQL, others.
· Full Audit Trails, Versioning, Security.
· Plenty of performance tuning available. For example, caching can be easily configured.
· Framework for “Actionable MDM.” Source data sets can be designated as Source of Record, and the Enterprise Master Services (virtual models) can be designated as the Master Data Definition, which incorporates all of the logic, notations, and security necessary to establish an Enterprise Service Layer.
For years IT used classic ETL to slowly build an expensive, brittle infrastructure. Using Agile ETL could have brought cheaper, faster, and more flexible infrastructure.
As you move forward toward enterprise use of Data Virtualization, why not start out with Agile DV and avoid the hidden pitfalls of most Data Virtualization platforms?